Language-based Colorization of Scene Sketches
Sun Yat-sen University1,
Huawei Noah's Ark Lab2,
Google3, City University of Hong Kong4
Google3, City University of Hong Kong4
Accepted by SIGGRAPH Asia 2019
A. System Overview
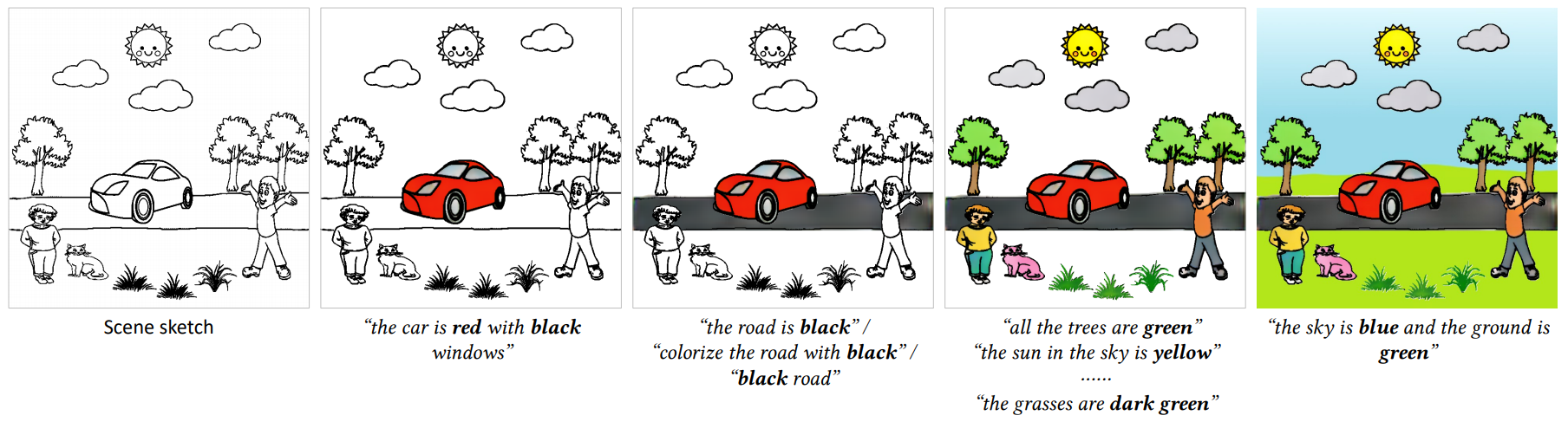
 Our system supports two-mode interactive colorization for a given input scene sketch and text-based colorization instructions, using three models, namely, the instance matching model, foreground colorization model, and background colorization model. It is not necessary to colorize foreground objects before background regions.
Our system supports two-mode interactive colorization for a given input scene sketch and text-based colorization instructions, using three models, namely, the instance matching model, foreground colorization model, and background colorization model. It is not necessary to colorize foreground objects before background regions.
B.1 Instance Matching Model
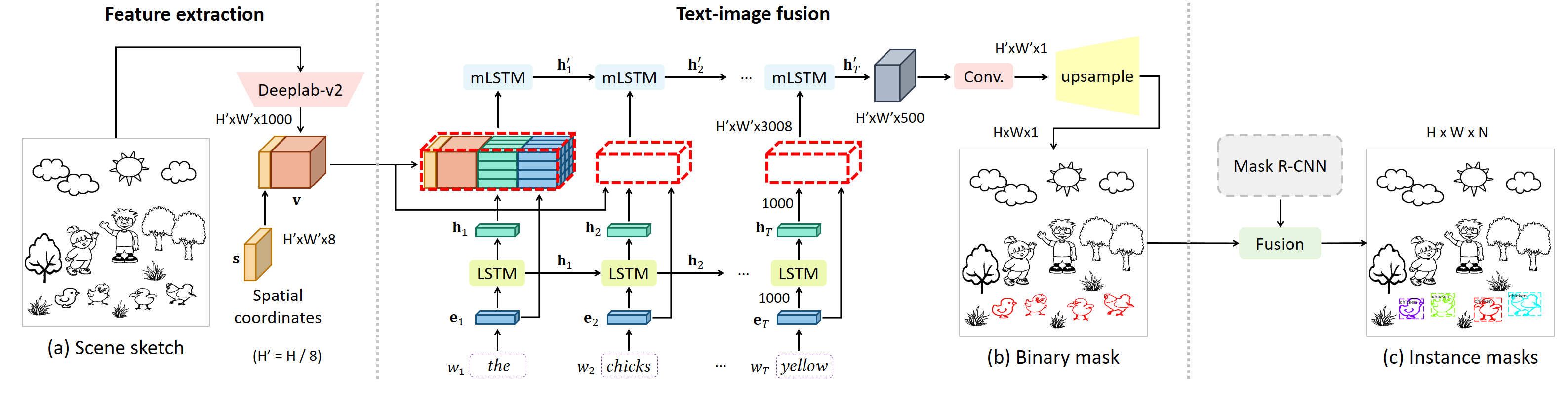 This network is trained in an end-to-end manner to obtain the binary mask (shown in (b)). In the inferring phase, the generated binary mask is fused with the instance segmentation results generated by Mask R-CNN to obtain the final results.
This network is trained in an end-to-end manner to obtain the binary mask (shown in (b)). In the inferring phase, the generated binary mask is fused with the instance segmentation results generated by Mask R-CNN to obtain the final results.
B.2 Foreground Colorization Model
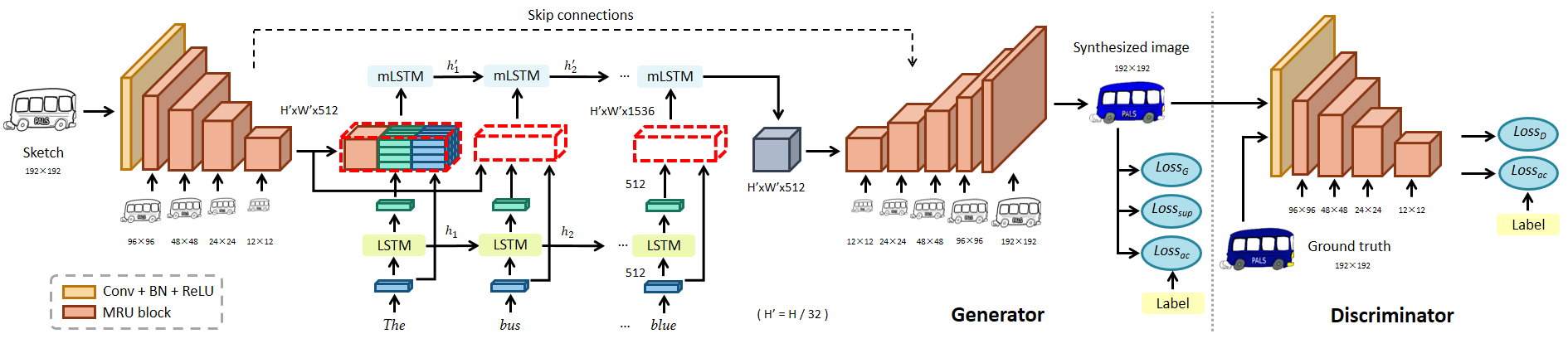 This network is able to colorize objects from different categories. The generator has a U-Net architecture based on MRU blocks, with skip connections between mirrored layers and an embedded RMI fusion module consisting of LSTM text encoders and multimodal LSTMs (mLSTM). It is referred to as the FG-MRU-RMI network for conciseness in the paper.
This network is able to colorize objects from different categories. The generator has a U-Net architecture based on MRU blocks, with skip connections between mirrored layers and an embedded RMI fusion module consisting of LSTM text encoders and multimodal LSTMs (mLSTM). It is referred to as the FG-MRU-RMI network for conciseness in the paper.
B.3 Background Colorization Model
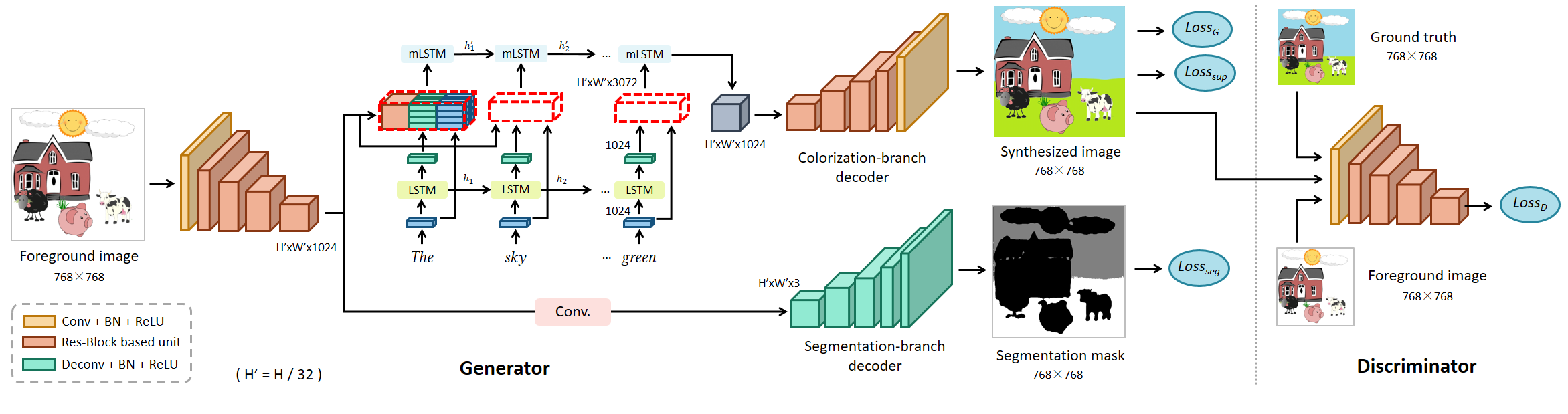 This network consists of an image encoder built on residual blocks (Res-Block), a fusion module, a two-branch decoder, and a Res-Block based convolutional discriminator. It is referred to as the BG-RES-RMI-SEG network in the paper.
This network consists of an image encoder built on residual blocks (Res-Block), a fusion module, a two-branch decoder, and a Res-Block based convolutional discriminator. It is referred to as the BG-RES-RMI-SEG network in the paper.
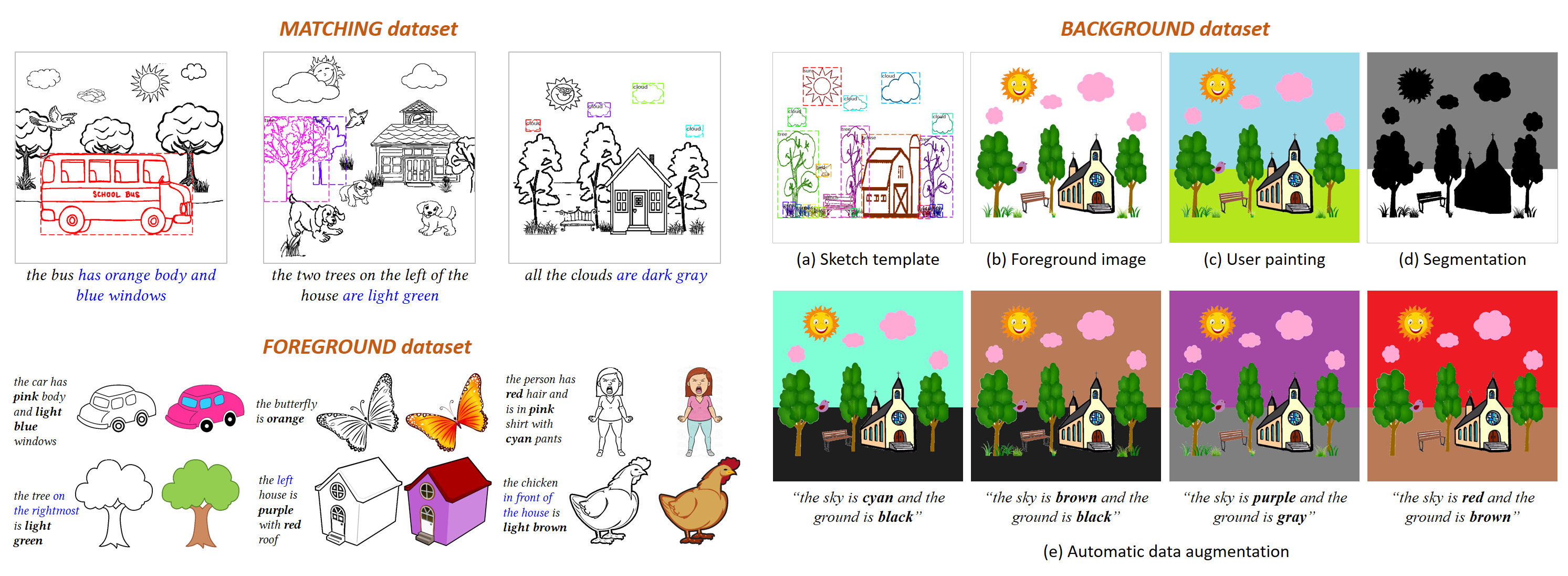 We have built three large-scale datasets for language-based scene sketch colorization:
We have built three large-scale datasets for language-based scene sketch colorization:
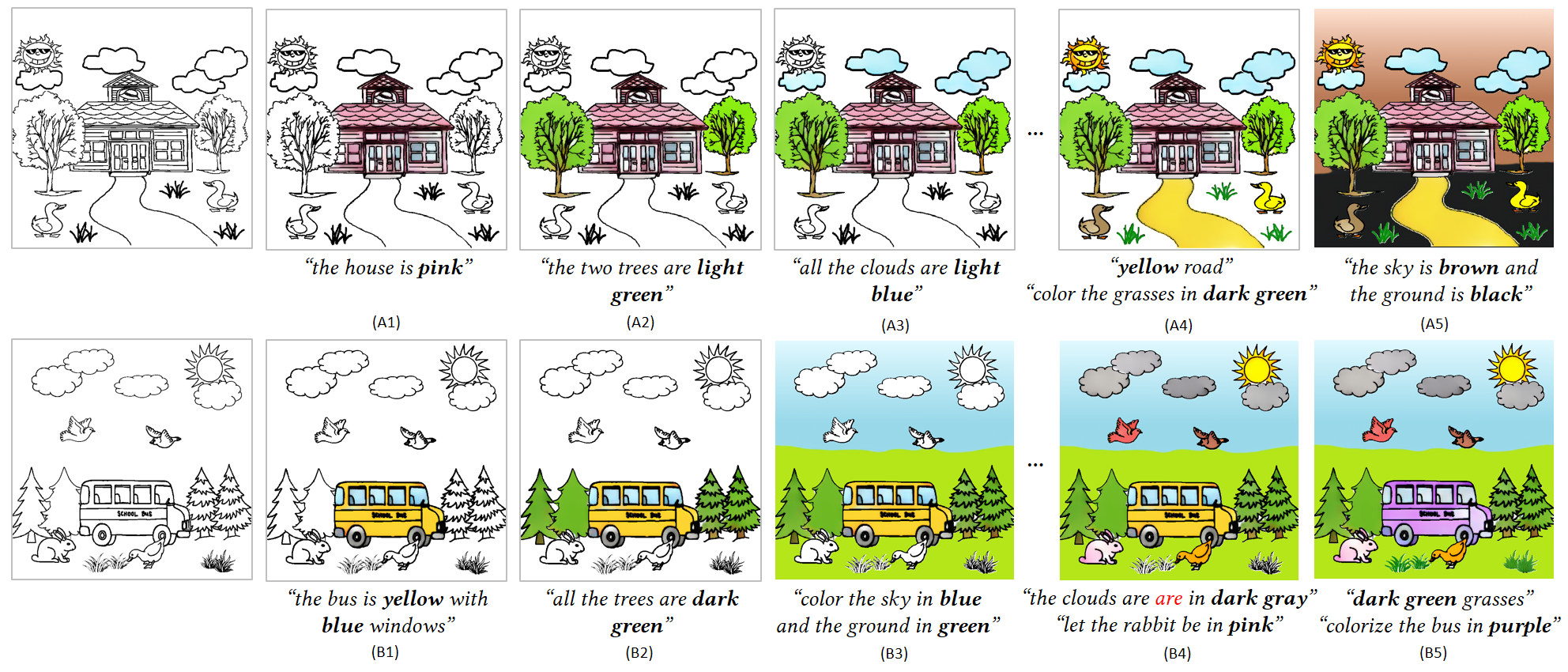
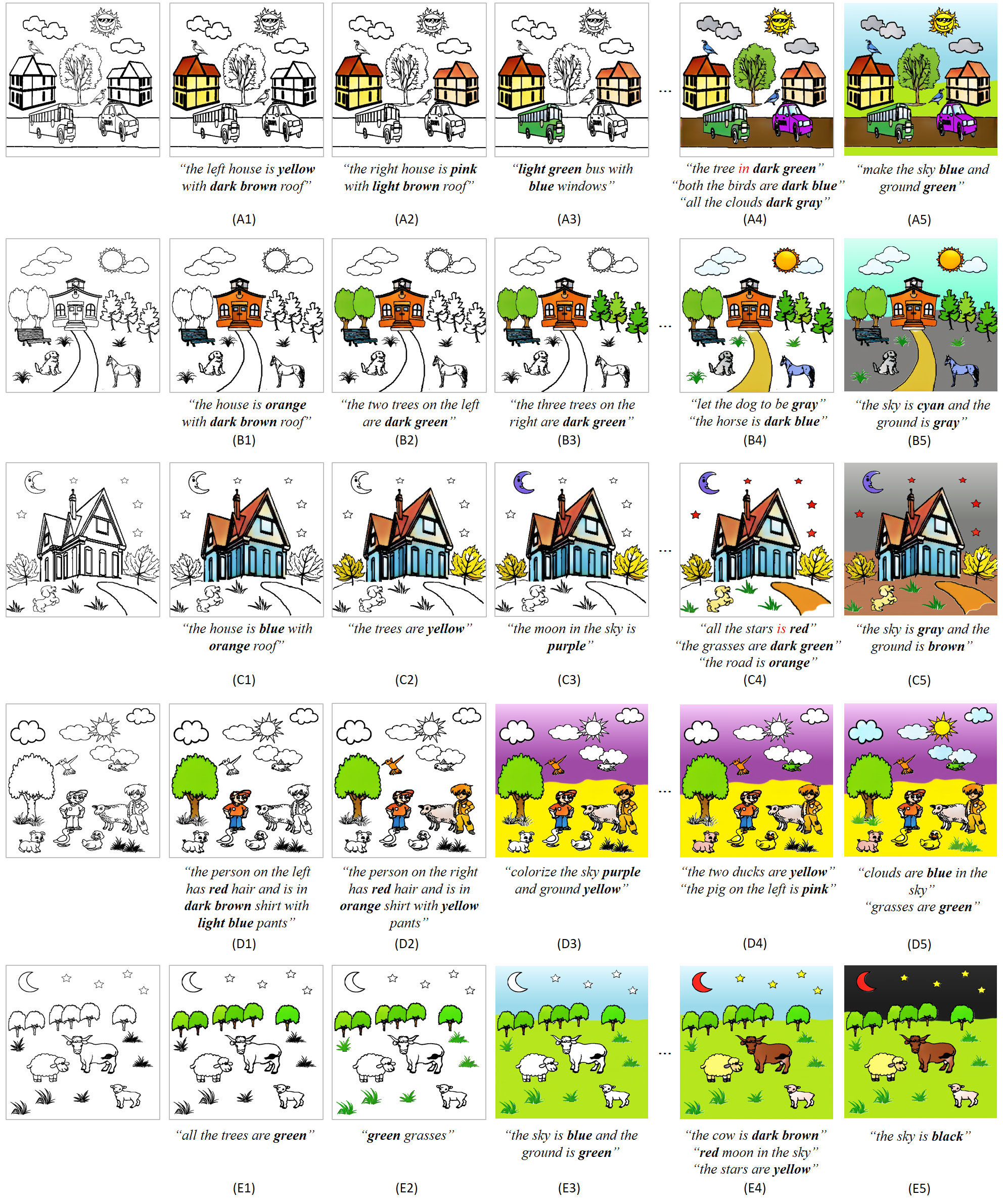 *For more results, please see main paper and the supplementary material.
*For more results, please see main paper and the supplementary material.
@article{zouSA2019sketchcolorization,
title = {Language-based Colorization of Scene Sketches},
author = {Zou, Changqing and Mo, Haoran and Gao, Chengying and Du, Ruofei and Fu, Hongbo},
journal = {ACM Transactions on Graphics (Proceedings of ACM SIGGRAPH Asia 2019)},
year = {2019},
volume = 38,
number = 6,
pages = {233:1--233:16}
}